If you’re a fan of reading our blog posts, you might have observed that a lot of the action in the Kafka producer-storage-consumer pipeline happens on the producer side.
The producer is the component that sends data to the Kafka broker(s) and is also in charge of making several decisions such as topic names, messages content, and topic settings. When data is sent to Kafka, the brokers are not going to modify such settings, but they do store everything as it is sent. In turn, the consumers will read the data based on the decisions made by the producer. For example, a consumer can read the data only if it reads from the topic name chosen by or agreed upon with the producer.
One such setting the producer is in charge of is called compression.
What is compression?
Since the early days of computers, users have needed to store data. While computers are very helpful while doing calculations, it is also true that having persistent storage is a fundamental part of the user experience. Persistent data is guaranteed by a finite resource whether it is a floppy disk (does anybody out there still use a floppy reader?) or a multi-terabyte disk, your disk is probably going to run out of space sooner or later.
One widely used way to store more data than your media can normally handle is to compress the data being stored. Basically, when compressed, the data gets coded in a way that is more efficient than plaintext, delegating the process to software that relies on a dictionary with the goal of using a fraction of the original space.
Without the need of having a degree in data compression, what we need to know is that there are several algorithms available to compress our beloved Kafka data for more efficient storage.
Feel free to dig deeper into data compression with this Wikipedia article: https://en.wikipedia.org/wiki/Data_compression.
How to use message compression
In order to enable compression on the producer, it is enough to set compression.type in your producer configuration. Valid values are ‘none’, ‘gzip’, ‘snappy’, ‘lz4’, or ‘zstd’, with ‘none’ as the default value.
When data is sent to Kafka with compression set to != none, it will be compressed according to the value passed to compression.type. The compression algorithm used is written in the metadata of the message and the Kafka broker will, as usual, store the received messages as they are bit by bit without caring about the content and how it is compressed.
In turn, the consumer will receive the data and, if compression was used, will transparently take care of decompressing it and make it usable.
To compress or not compress, that is the question
Unless there are valid reasons not to, compressing is always a good idea. There are many reasons to compress messages, and this picture is worth a thousand words.

Money? Yes. money, and time. And we know time is money, therefore: money^2.
When compression is used, space is saved because the messages become smaller in size. Saved space means that less total disk space is used, therefore less operational costs can be related to disk space.
But it is not only about disk space.
Smaller messages mean that less RAM is used, so therefore your Kafka instance will need less RAM, or it can allocate more RAM to buffering which, in turn, will save you disk IO whenever a consumer falls behind the allocated buffer.
More benefits
Because compressed messages are smaller, less bandwidth is required to move messages from producers to broker, between brokers when replication is enabled, and from brokers to consumers.
This is a timesaver! Why? Because messages will be delivered faster because they are compressed and smaller. If you already read our article about batch.size and linger.ms, then you should know that the bigger the batch, the more efficient the compression might work.
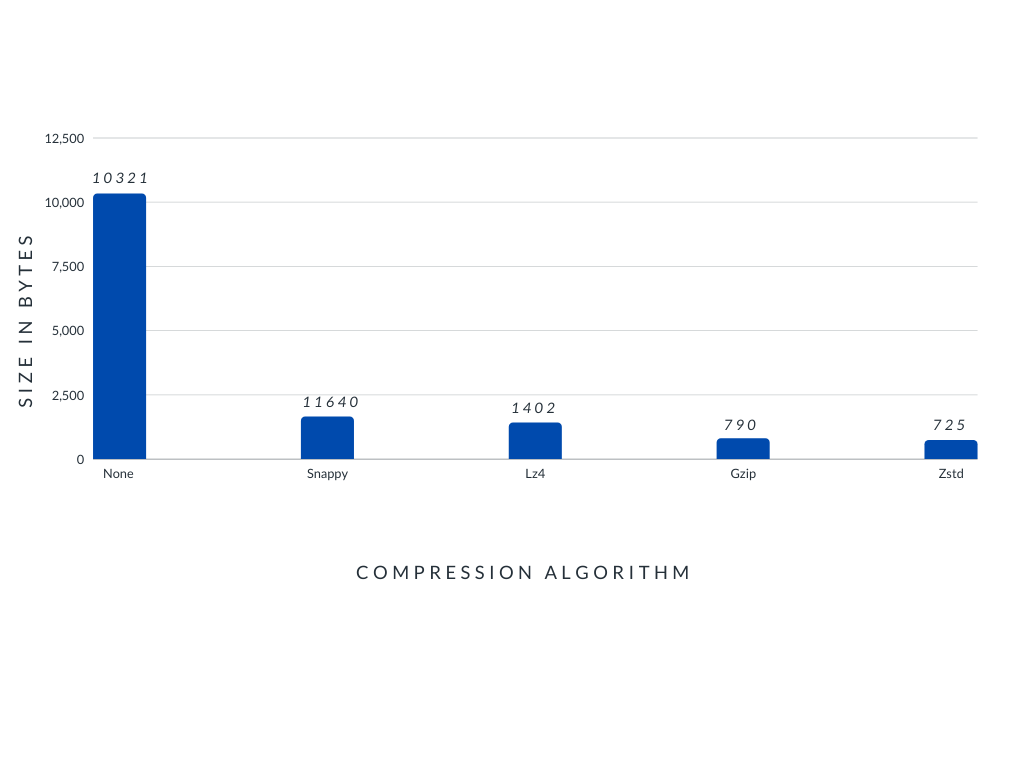 A comparison between compression options in our tests: zstd only took 7% of
the space compared to ‘none’.
A comparison between compression options in our tests: zstd only took 7% of
the space compared to ‘none’.
Something worth mentioning is that different kinds of data respond differently to the compression algorithms. Therefore, it is advised to to perform a test using your own data in order to choose the most efficient compression algorithm.
Also keep in mind that compression and decompression will utilize the CPU of the producer and the consumer respectively. Playing with the settings, like batch.size or linger.ms will attenuate the overhead, but there will still be a certain degree of overhead.
In our experience, the CPU increase is minor but it is of course something to take into consideration when planning the architecture of your pipeline, and during your benchmarks.
Happy compressing!
We hope that you found this information useful. If you have any questions or concerns regarding this blog post, send an email to support@cloudkarafka.com.
All the best,
The CloudKarafka Team
