Kafka is under many aspects the perfect tool to ingest and serve data in an efficient and scalable way. This article will explain how to optimize producers using linger.ms and batch.size.
Kafka’s separation-by-architecture explained
What makes Kafka a good fit in a devops setup is the ability to separate who sends data (the ‘producer’), from where the data is stored (Kafka instances called ‘brokers’), from whom is interested in the data and wants to read it (‘consumer’).
Even if consumers and producers live in the same ‘ecosystem’, they do not influence each other. This is true even Kafka itself is agnostic on how data should be stored on the disk. What is sent from the producer is stored in Kafka ‘as is’.
This separation-by-architecture allows a lot of freedom to producers on what kind of data is sent and how: the format of messages, batching, compression, partition keys, and much more are chosen by the producer. As the producer is the product of the developers in concertation with colleagues from the operations team, the whole production pipeline is kept in good order.
That is a real devops effort!
Producer optimization
Two producer-side settings we at CloudKarafka are frequently asked about are linger.ms and batch.size. These settings are tied to one another and come to the rescue when the producer is under stress.
When the producer load is moderate to heavy, and the assigned resources (CPU, RAM, and Network) cannot cope, it is definitely time to look into the producer settings in order to make a more efficient use of the resources, or to achieve a higher throughput.
It is also interesting to look into such settings if you plan to stress test your application, which is always considered a good practice.
However, if the load of your application will be low compared to the assigned resources, and/or you do not feel the need to optimize your producer, then you can better invest your time in reading about other producer-side settings without focusing too much on linger.ms and batch.size. You can always come back to this later.
The strategy of linger.ms vs batch.size
As you probably already know, producers are in charge of sending messages to a topic, and topics can have one or more partitions. Each time a message is ready to be sent to a specific partition, it can be grouped with other messages in order to create a so-called ‘batch of messages’ or, alternatively, it can be sent alone without waiting for other messages to be ready to be sent.
linger.ms refers to the time to wait before sending messages out to Kafka. It defaults to 0, which the system interprets as ‘send messages as soon as they are ready to be sent’.
batch.size refers to the maximum amount of data to be collected before sending the batch.
Kafka producers will send out the next batch of messages whenever linger.ms or batch.size is met first.
Similar to how messages are moved across the network, humans move through space, so we can make a comparison about cars and humans to better explain this concept.
linger.ms vs batch.size illustrated
There are small cars and big cars. And there are buses too. If we want to move from A to B, several possibilities are available:
-
Go to the public transport hub. As soon as one person is waiting, a car
picks that person up, no waiting. This is an example of linger.ms=0
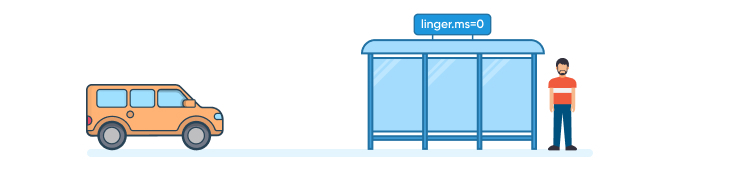
-
Go to the public transport hub and wait for the next bus to leave. A bus is
going to leave every 5 minutes, or when there are 10 people waiting in line.
This is an example of linger.ms=5min and batch.size=10
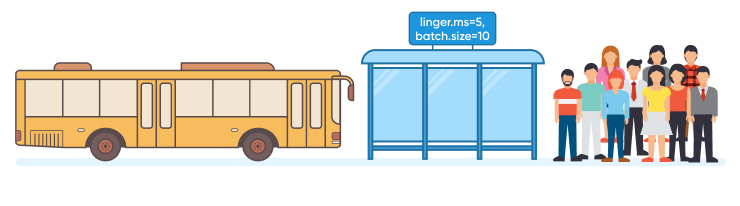
Both options might be convenient and have their pros and cons, depending on several factors, such as how many people want to travel, how important it is to get to the destination ASAP, or perhaps how large the highway is.
For instance, if many people are willing to travel at the same time, option 1 will result in many cars leaving within a short time and it might not be the most efficient way to travel.
Similarly, if your consumer is sending a lot of messages a more efficient choice would be to group them together and send them out in a batch.
Messages that have to wait for linger.ms or batch.size to be fulfilled will experience a delay, which, in the worst case scenario, is as long as linger.ms (but on average, half of that).
For many applications it is acceptable to wait a few milliseconds but it is always something to keep in mind when planning the architecture of your producer.
Pro Tips
- If you are using compression with batching, then you will notice that a compressed batch size is smaller than one compressed message times all the messages in the batch. That means a compressed batch is going to be smaller. And smaller means less disk space, less network bandwidth used and indeed more RAM available for your operations.
- It is a best practice to find out if linger.ms or batch.size are met first under production load. You might realize your messages are big in size and a few fit in a batch, or your batch.size is never met and only linger.ms is effective.
In this article we did a dive into two settings tied one to another: batch.size and linger.ms, describing fine-tune of Kafka performance. To set up your own instance and see the results of linger.ms and batch.size on Kafka, try them out at CloudKarafka
