Maintaining a world-leading B2B platform for music distribution is a monumental task. Major points of consideration include the performance, availability and scalability of the platform. Thinking ahead for the future, 7digital relied on Apache Kafka and CloudKarafka database replication to create a solid, easy-to-scale product. 7digital Head of Development, Hanif Jameel, explains how the music-as-a-service company became a global powerhouse:
7digital was founded in 2004 and has evolved to become one of the world’s leading B2B music technology companies. Their unparalleled whitebox solution and flexible API enables their customers and partners to easily create unique, captivating music experiences by managing the complexity inherent in music data, delivery, compliance and reporting.
The company offers music integrations for companies via an agnostic set of APIs, including a catalog, streaming, rights holder reporting, playlisting and more and today has 45 live customers serving 82 territories including Fender, Universal Music Group, Triller, and Global Eagle Entertainment. CloudKarafka had a chat with Hanif Jameel, Head of Development at 7digital to give the full story.
Apache Kafka for database replication
7digital manages a world-class catalog of music across more territories and music formats than any other B2B music service. 7digital’s flexible API allows any company creating its own music offering to harness the power of this catalog using a robust set of sortable data aspects including artist information, track titles, track listings, publishers and license rights, usage rights, new music releases, and much more.
The meta-information arrives in the music-industry standardized format and is then placed into a master catalog. The master catalog is constantly growing at an incredible rate, with about 1 million tracks and associated metadata added to the catalog every month.
While 7digital uses Apache Kafka for database replication, its architecture is built upon multiple aspects and customer requests. This article explains the Apache Kafka portion of the 7digital architecture.
The architecture
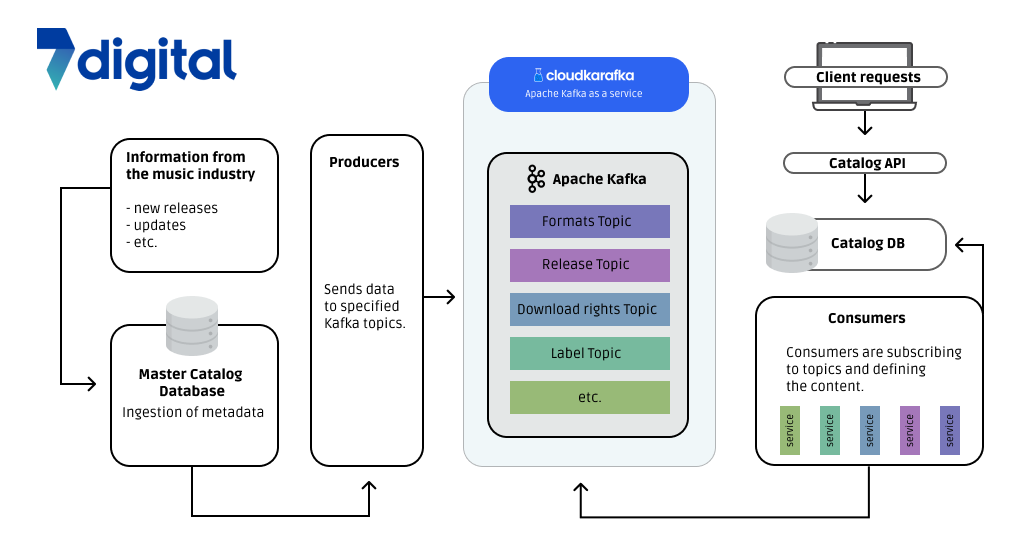
The 7digital catalog uses two databases. One database ingests all the metadata from the music industry (the Master Catalog), while the other database is primarily used to support customers with the information needed to use the catalog API, called the Catalog Database. The data is replicated and sorted from the Master Catalog, via Apache Kafka and then placed onto the Catalog Database. The consumers in the architecture run within AWS Fargate (a serverless compute engine), and Apache Kafka (hosted by CloudKarafka). This way, 7digital's operational overhead of running the system is much reduced.
The high rate of data coming into the system requires it to be handled quickly and with the order of events being maintained. The data is processed as follows:
- Content is ingested and stored in a SQL database.
- In SQL Server, CDC (Change Data Capture) is used to fetch the data and send it into Kafka via a topic-specific producer where it is sorted into given topics like format, release, downloads, etc.
- Consumers in AWS Fargate subscribe to these topics. They pull data from Apache Kafka to keep the read-optimized, Catalog Database up-to-date.
- The Catalog API, which is used by the customers, connects to the Catalog Database and provides the customer with the information needed.
Why Apache Kafka
The essential property of the Catalog Database is the ability to handle the large amount of data needed for the Catalog API. In the process of reviewing options, 7digital found that the Apache Kafka database replicating tool provided scalability for what they need and beyond. By simply scaling the producers, Apache Kafka can ingest an increasing amount of data from the industry and still provide the application with resiliency. Kafka also maintains the ordering of messages that the company needs for a fulfilling and successful replication system.
Today, the company sends ~500 messages per second in Kafka to ensure the Catalog Database is up to date and thereby ensuring that its customers are presented with a huge choice of songs from both existing and emerging rights holders to suit their customers’ needs.
Why Kafka instead of a regular database replication?
A common practice to keep data safe in any system is to store a copy of each entry in a separate database. This is usually achieved with regular database replication, however, with two distinct types of databases, 7digital’s architecture created a barrier to this approach. The team managed to overcome this challenge by using Apache Kafka to build a database-agnostic replication mechanism. Kafka allows 7digital to replicate large amounts of ordered data from one database to the other, which then later feeds the Catalog API.
Since the data is already in Kafka ready to be consumed, it was easy for the team to connect more services to process the same data. One example for 7digital was to set up an alternative catalog API to help a partner integrate based on industry-standard identifiers (DDEX party id, UPC and ISRC) so that they did not require 7digital's internal track identifiers to integrate.
Another Kafka advantage is the ability to reset the offset and go back in history, and 7digital used that history mechanism in the early stages of the project. During the setup phase it became necessary to wipe the databases and read the data back in. With the infinite retention setting on all the topics, consumers should be reset to read from message zero, instead of requiring data to be replayed into Kafka.
The CloudKarafka Advantage
Hanif and his team were familiar with Apache Kafka as a solution for log-based data replication and started by running an in-house Kafka cluster on EC2. Strategically, the team realized that managing Kafka was an increasing overhead to maintain and the team lacked confidence in their self-hosted environment for the production workloads.
CloudKarafka enabled the team to focus on the use of Kafka and their integration with it, rather than running the cluster itself. Hanif also values the dashboard, which makes it easy for developers and data teams to get stats on the cluster and check the status/configuration of each topic.
We're happy with the service, it's now a reliable part of our infrastructure.
- Hanif Jameel, Head of Development at 7digital
We hope you enjoyed reading about 7digital’s Apache Kafka experience in this blog post. If you are interested in learning more about Apache Kafka hosted solutions or how to get started with CloudKarafka, visit the CloudKarafka blog.
All the best,
The CloudKarafka Team
If you have any questions or concerns regarding this blog post, send an email to support@cloudkarafka.com.
