The release of librdkafka 1.0.0 brings a new feature to those who are not on the Java or JVM stack. If you use Apache Kafka, and do not use Java, then you’ll likely be depending on librdkafka. So with the release of librdkafka 1.0.0, we thought it was the perfect time to cover the Idempotent Producer feature, what it is and why you might want to enable it.
What is the Idempotent Producer feature?
When a producer sends messages to a topic, things can go wrong, such as short connection failures. When this happens, any messages that are pending acknowledgements can either be resent or discarded. The messages may have been successfully written to the topic, or not, there is no way to know. If we resend then we may duplicate the message, but if we don’t resend then the message may essentially be lost.
Also, resending messages can cause message ordering to go wrong. So we can end-up with messages delivered twice and out-of-order.
The idempotent producer feature addresses these issues ensuring that messages always get delivered, in the right order and without duplicates.
Language Binding Support
The Apache Kafka brokers and the Java client have supported the idempotent producer feature since version 0.11 released in 2017. But other language clients that depends on the C++ library librdkafka have not had support. That has changed with the release of librdkafka 1.0.0 Librdkafka is a C++ language binding for Apache Kafka that many other client libraries depend on. Libraries in a host of languages (Python, C#, Go, Node.js, Erlang, Ruby and more ) are simply wrappers of librdkafka and so have been unable until now to enjoy this feature.
Enabling Idempotent Producer
All you need to do to turn this feature on is use the producer configuration enable.idempotence=true. You will also want to set a high value for message.send.max.retries (alias retries). Librdkafka imposes the limit of 10000000. You may be thinking that 10000000 is ridiculously high, but librdkafka will perform retries at very short intervals and can quickly exhaust your retry limit if set low.
For example, with the Confluent Python client:
producer = Producer({'bootstrap.servers': ‘localhost:9092’,
'message.send.max.retries': 10000000,
'enable.idempotence': True})Note that there are a couple of limitations when using this feature.
Limitation 1: Acks=All
For one, you can only use acks=all. If you set acks to 0 or 1 then you’ll see the following error (Python example):
cimpl.KafkaException: KafkaError{code=_INVALID_ARG,val=-186,str="Failed to create producer: `acks` must be set to `all` when `enable.idempotence` is true"}You can choose not to set acks at all, and by using enable.idempotence=true, the acks configuration will automatically be set to all for you.
Limitation 2: max.in.flight.requests.per.connection <= 5
You must either leave max.in.flight.requests.per.connection (alias max.in.flight) left unset so that it be automatically set for you or manually set it to 5 or less. If you leave it explicitly set to a value higher than 5 you’ll see:
cimpl.KafkaException: KafkaError{code=_INVALID_ARG,val=-186,str="Failed to create producer: `max.in.flight` must be set <= 5 when `enable.idempotence` is true"}How it Works
When enable.idempotence is set to true, no manual retries are required, in fact performing retries in your application code will still cause duplicates. Leave the retries to your client library, it is totally transparent to you as a developer.
So retries are taken of, but how can the broker identify duplicate messages and discard them?
Each producer gets assigned a Producer Id (PID) and it includes its PID every time it sends messages to a broker. Additionally, each message gets a monotonically increasing sequence number. A separate sequence is maintained for each topic partition that a producer sends messages to. On the broker side, on a per partition basis, it keeps track of the largest PID-Sequence Number combination is has successfully written. When a lower sequence number is received, it is discarded.
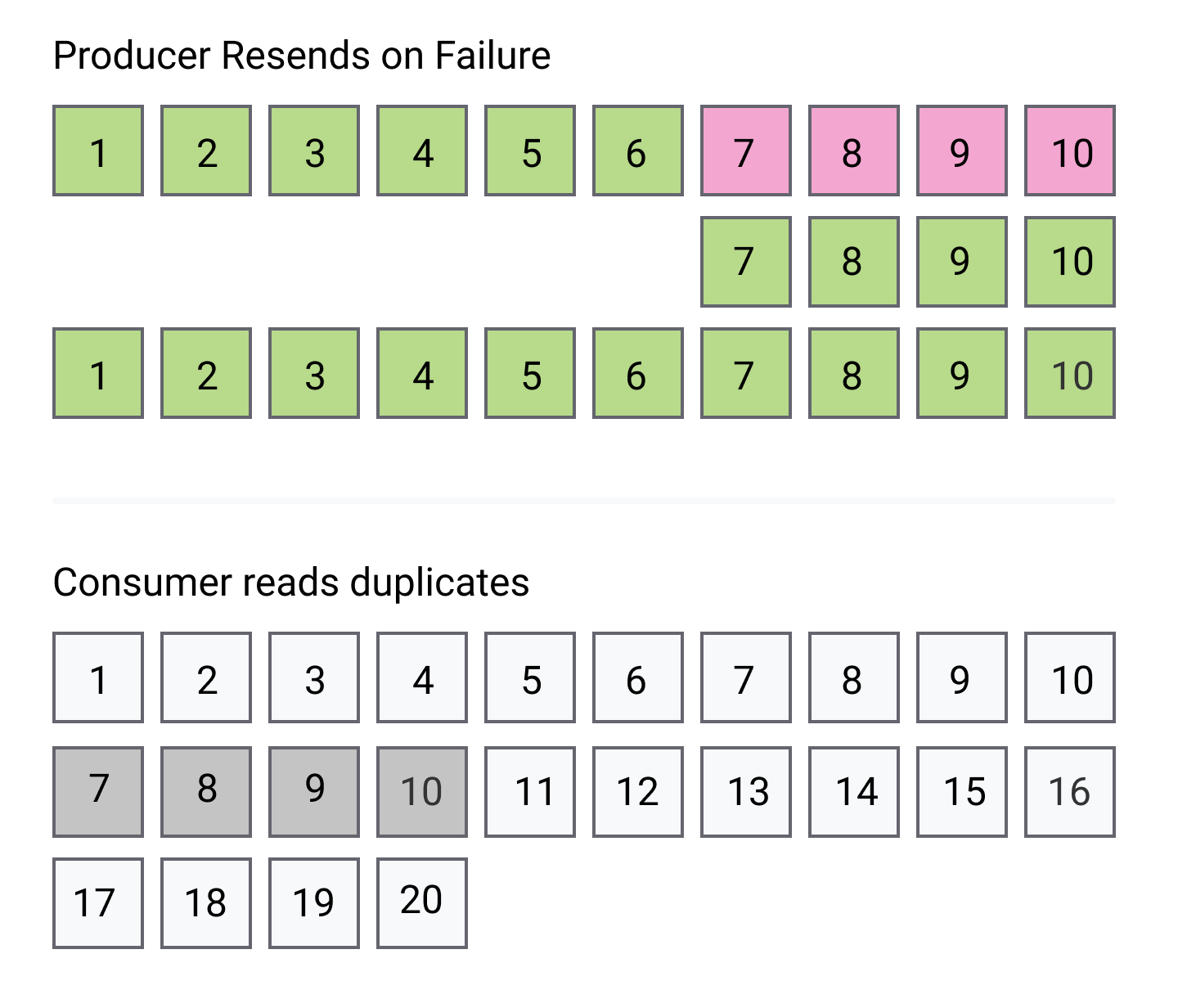
Let’s go through an example. Let’s see what could happen without idempotence enabled.
With idempotence disabled we could have the situation where a producer is asynchronously sending messages to a topic partition, say messages M1 to M10. Just after sending message 7 the connection fails. It has received acknowledgements for messages 1 to 3. So messages 4, 5, 6 and 7 are resent, then messages 8 to 10. But the broker was in fact able to write all but message 7 to the partition, so now the messages stored in the partition are: M1, M2, M3, M4, M5, M6, M4, M5, M6, M7, M8, M9, M10
But with idempotence enabled, each message comes with a PID and sequence number:
- M1 (PID: 1, SN: 1) - written to partition. For PID 1, Max SN=1
- M2 (PID: 1, SN: 2) - written to partition. For PID 1, Max SN=2
- M3 (PID: 1, SN: 3) - written to partition. For PID 1, Max SN=3
- M4 (PID: 1, SN: 4) - written to partition. For PID 1, Max SN=4
- M5 (PID: 1, SN: 5) - written to partition. For PID 1, Max SN=5
- M6 (PID: 1, SN: 6) - written to partition. For PID 1, Max SN=6
- M4 (PID: 1, SN: 4) - rejected, SN <= Max SN
- M5 (PID: 1, SN: 5) - rejected, SN <= Max SN
- M6 (PID: 1, SN: 6) - rejected, SN <= Max SN
- M7 (PID: 1, SN: 7) - written to partition. For PID 1, Max SN=7
- M8 (PID: 1, SN: 8) - written to partition. For PID 1, Max SN=8
- M9 (PID: 1, SN: 9) - written to partition. For PID 1, Max SN=9
- M10 (PID: 1, SN: 10) - written to partition. For PID 1, Max SN=10
If a broker fails and a new leader is elected, deduplication still continues to work because the PID and sequence number is included in the message data. Because all messages are replicated to followers, a follower that is elected as the new leader already has all the data it needs to perform deduplications.
When should producer idempotence be enabled?
If you already use acks=all then there is no reason not to enable this feature. It works flawlessly and without an additional complexity for the application developer. It is just a no-brainer decision.
If you currently use acks=0 or acks=1 for reasons of latency and throughput then you might consider staying away from this feature. Acks=all increases latencies and latency variability. If you already use acks=0 or acks=1 then you probably value the performance benefits over data consistency.
Appendix: Duplication Examples
We can actually show the effects of retries without idempotence enabled with a little test code. Using the Confluent Python client we can send a series of messages while periodically killing the TCP connection and even making brokers fail at random.
The test consists of one producer sending messages whose content is an integer. Each message that is sent is sent with an incremented value, creating a monotonically increasing sequence, such as 1, 2, 3, 4, 5, 6, 7… This allows our consumer to detect when it has received a duplicate or out-of-order message. The consumer prints all duplicate or out-of-order messages. All non-duplicated messages are sampled (due to message volume).
There is a setting that can affect the pattern of duplication and overall throughput called queue.buffering.max.ms with alias linger.ms. This producer configuration allows us to accumulate messages before sending them, creating larger or smaller batches. Larger batches increase throughput, while also increasing latency as messages are accumulated in memory for a period before sending.
When running this test with the default value of 0 for queue.buffering.max.ms. We see the following pattern of duplicates:
Sample msg: m=1
Sample msg: m=30000
Msg: m=37217 DUPLICATE
Msg: m=47413 DUPLICATE
Msg: m=57511 DUPLICATE
Sample msg: m=59997
Msg: m=65899 Last-acked=65929 JUMP BACK 30 DUPLICATE
Msg: m=65900 DUPLICATE
Msg: m=65901 DUPLICATE
Msg: m=65902 DUPLICATE
Msg: m=65903 DUPLICATE
Msg: m=65904 DUPLICATE
Msg: m=65905 DUPLICATE
Msg: m=65906 DUPLICATE
Msg: m=65907 DUPLICATE
Msg: m=65908 DUPLICATE
Msg: m=65909 DUPLICATE
Too many duplicates...
Run of duplicates ended with 30 duplicates and msg:m=65929
Msg: m=76251 DUPLICATE
Msg: m=86304 DUPLICATE
Sample msg: m=89964
Msg: m=96656 DUPLICATE
Msg: m=107943 DUPLICATE
Sample msg: m=119962
Msg: m=130235 DUPLICATE
Msg: m=140334 Last-acked=140335 JUMP BACK 1 DUPLICATE
Msg: m=140335 DUPLICATE
Sample msg: m=149959
Msg: m=165304 DUPLICATE
Msg: m=175484 DUPLICATE
Sample msg: m=179957
Msg: m=202195 DUPLICATE
Sample msg: m=209956
Sample msg: m=239956
Sample msg: m=269956
Msg: m=287965 Last-acked=287968 JUMP BACK 3 DUPLICATE
Msg: m=287966 DUPLICATE
Msg: m=287967 DUPLICATE
Msg: m=287968 DUPLICATE
Msg: m=298220 Last-acked=298221 JUMP BACK 1 DUPLICATE
Msg: m=298221 DUPLICATE
Sample msg: m=299950
Msg: m=308318 DUPLICATE
Msg: m=318342 DUPLICATE
Msg: m=318342 Last-acked=318474 JUMP BACK 132 DUPLICATE
Msg: m=318343 DUPLICATE
Msg: m=318344 DUPLICATE
Msg: m=318345 DUPLICATE
Msg: m=318346 DUPLICATE
Msg: m=318347 DUPLICATE
Msg: m=318348 DUPLICATE
Msg: m=318349 DUPLICATE
Msg: m=318350 DUPLICATE
Msg: m=318351 DUPLICATE
Msg: m=318352 DUPLICATE
Too many duplicates...
Run of duplicates ended with 132 duplicates and msg:m=318474
Msg: m=328377 DUPLICATE
Sample msg: m=329814
Msg: m=338414 DUPLICATE
Sample msg: m=359813
Msg: m=362442 Last-acked=362443 JUMP BACK 1 DUPLICATE
Msg: m=362443 DUPLICATE
Sample msg: m=389811
Sample msg: m=419811
Sample msg: m=449811
RESULTS------------------------------------
Confirmed count: 453346 Received count: 463537 Unique received: 463348
Duplication count: 189
RESULTS END------------------------------------In total, 453346 messages sent with 189 duplicates. Duplicates tended to happen individually all in small blocks.
When we set queue.buffering.max.ms to 100ms, we see a very different pattern of duplication.
Sample msg: m=1
Sample msg: m=300000
Sample msg: m=600000
Sample msg: m=900000
Sample msg: m=1200000
Sample msg: m=1500000
Sample msg: m=1800000
Sample msg: m=2100000
Sample msg: m=2400000
Sample msg: m=2700000
Sample msg: m=3000000
Sample msg: m=3300000
Sample msg: m=3510000
Msg: m=3518222 Last-acked=3521706 JUMP BACK 3484 DUPLICATE
Msg: m=3518223 DUPLICATE
Msg: m=3518224 DUPLICATE
Msg: m=3518225 DUPLICATE
Msg: m=3518226 DUPLICATE
Msg: m=3518227 DUPLICATE
Msg: m=3518228 DUPLICATE
Msg: m=3518229 DUPLICATE
Msg: m=3518230 DUPLICATE
Msg: m=3518231 DUPLICATE
Msg: m=3518232 DUPLICATE
Too many duplicates...
Run of duplicates ended with 3484 duplicates and msg: m=3521706
Sample msg: m=3626515
Msg: m=3643252 Last-acked=3646268 JUMP BACK 3016 DUPLICATE
Msg: m=3643253 DUPLICATE
Msg: m=3643254 DUPLICATE
Msg: m=3643255 DUPLICATE
Msg: m=3643256 DUPLICATE
Msg: m=3643257 DUPLICATE
Msg: m=3643258 DUPLICATE
Msg: m=3643259 DUPLICATE
Msg: m=3643260 DUPLICATE
Msg: m=3643261 DUPLICATE
Msg: m=3643262 DUPLICATE
Too many duplicates...
Run of duplicates ended with 3016 duplicates and msg: m=3646268
Sample msg: m=3653498
Sample msg: m=3923498
Sample msg: m=4193498
Sample msg: m=4523498
Sample msg: m=4823498
Sample msg: m=5123498
Sample msg: m=5423498
Sample msg: m=5723498
Sample msg: m=6023498
Sample msg: m=6323498
Sample msg: m=6623498
Sample msg: m=6713498
RESULTS------------------------------------
Confirmed count: 6723843 Received count: 6733622 Unique received: 6727120
Duplication count: 6502
RESULTS END------------------------------------Instead of multiple individual or small blocks of duplicates, we see fewer larger blocks. This is due to the fact that fewer, larger batches of messages are sent using this configuration. While there were more duplicates, an order of magnitude more messages were sent (due to the more efficient producer configuration).
With enable.idempotence set to true, we never see a single duplicate, despite failing brokers and TCP connections.
If you have any questions, you can reach out to support@cloudkarafka.com.
Best, CloudKarafka Team
