After numerous years of experience working with hosted Apache Kafka solutions, the CloudKarafka Team finally put together a Best Practice blog post to guide you into how to best tune your Kafka Cluster to meet your high-performance needs.
In this guide, you find important tips, broker configurations, common errors and most importantly - we give you our best recommendations for optimization of your Apache Kafka Cluster.
Below follows a short overview of Apache Kafka and important concepts are defined - It’s a quick refreshment of your current Kafka knowledge. If you are new to Apache Kafka, we recommend you to first look into our Beginner Guide. Part 1, part 2 and part 3 of Performance optimization for Apache Kafka will all include optimization tips for Kafka, divided up between Producers, Brokers, and Consumers.
 Part 1 Apache Kafka Producers
Part 1 Apache Kafka Producers
 Part 2 Apache Kafka Brokers
Part 2 Apache Kafka Brokers
 Part 3 Apache Kafka Consumers
Part 3 Apache Kafka Consumers
Apache Kafka Refreshment
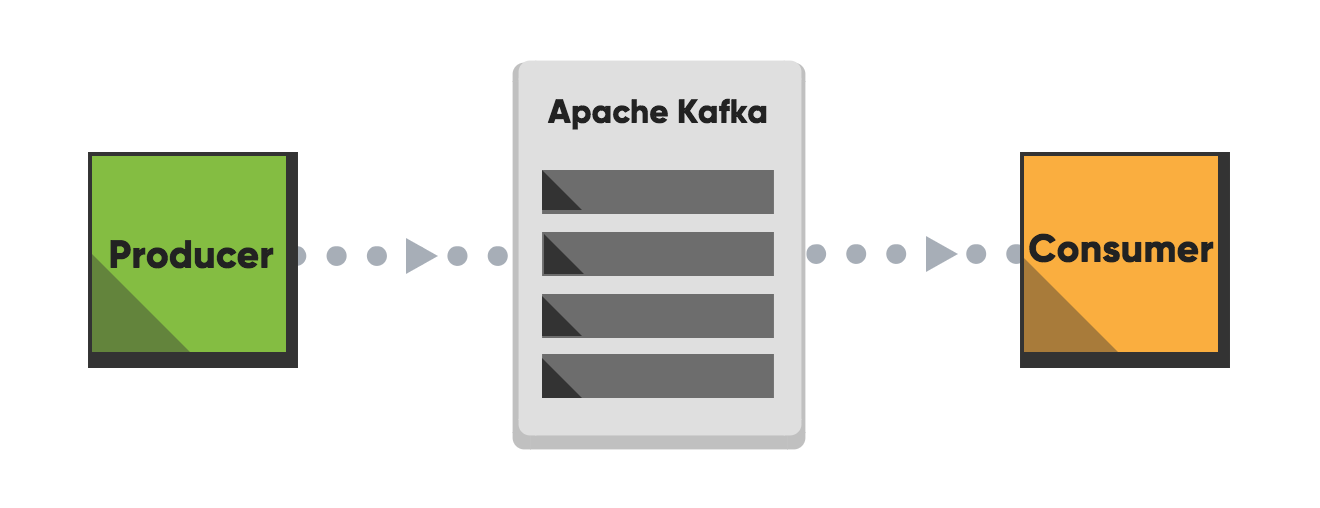
Apache Kafka is a distributed stream processing platform for big data. It’s a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system. Kafka store streams of records. Unlike most messaging systems, the log (the message queue) is persistent.
The log stream in Kafka is called a topic. Producers publish, (append), their records to a topic, and consumers subscribe to one or more topics. A Kafka topic is just a sharded write-ahead log.
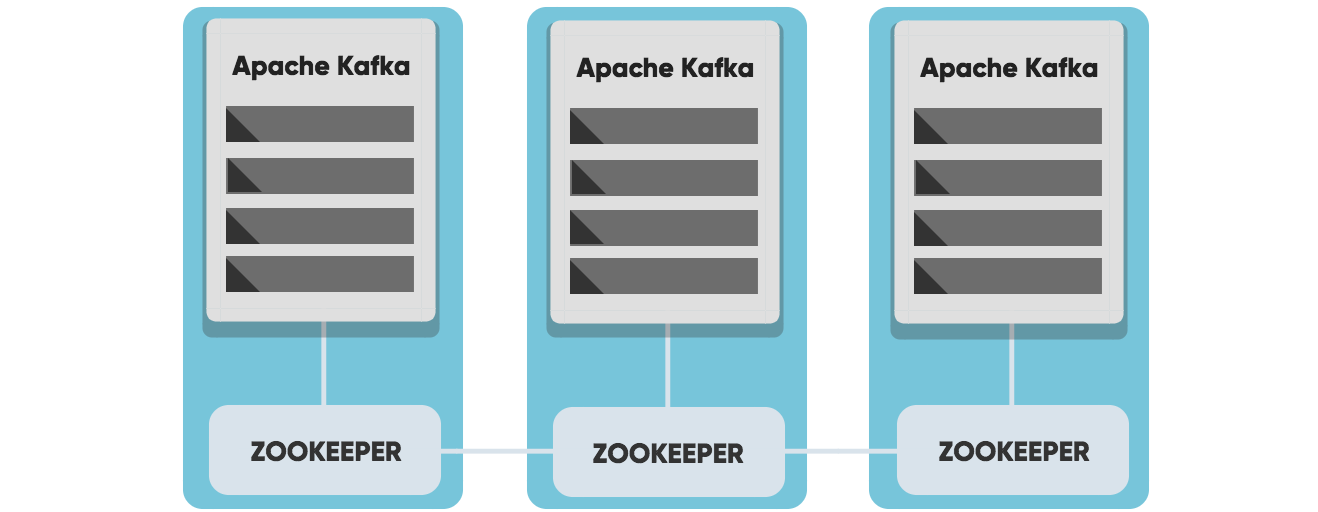
Kafka uses ZooKeeper to manage the cluster, Zookeeper keeps track of the status of Kafka cluster nodes, and it also keeps track of Kafka topics, partitions, etc.
Important Concepts
Broker
A Kafka cluster consists of one or more servers called Kafka brokers. The Kafka broker is mediating the conversation between different computer systems, like a queue in a message system. Nodes in a Kafka cluster communicate by sharing information between each other directly or indirectly using Zookeeper.
Producer
A producer writes data (records) to brokers.
Consumer
A consumer reads data (records) from the brokers.
Topics
Each Broker can have one or more topics. A Topic is a category/feed name to which messages are stored and published. If you wish to send a message you send it to a specific topic and if you want to read a message you read it from a specific topic. Messages published to the cluster will stay in the cluster until a configurable retention period has passed. Kafka retains all messages for a set amount of time or until a configurable size is reached.
Partition
Topics are split into partitions, which can be replicated between nodes. Consumers cannot consume messages from the same partition at the same time.
Record
Data sent to and from the broker is called a record, a key-value pair. The record contains the topic name and partition number. The Kafka broker keeps records inside topic partitions.
Consumer group
A consumer group includes the set of consumers that are subscribing to a specific topic. Kafka consumers are typically part of a consumer group. Each consumer in the group is assigned a set of partitions from where to consume messages. Each consumer in the group will receive messages from different subsets of the partitions in the topic. Consumer groups enable multi-machine consumption from Kafka topics.
Offset
Kafka topics are divided into a number of partitions, which contains messages in an unchangeable sequence. Each message in a partition is assigned and identified by its unique offset.
ZooKeeper
Zookeeper is a software developed by Apache that acts as a centralized service and keeps track of the status of the Kafka cluster nodes, and it also keeps track of Kafka topics, partitions, etc.
Let's continue...
Get started with Apache Kafka
We offer fully managed Apache Kafka clusters with epic performance & superior support
