The CloudKarafka team announces Kafka mirroring with MirrorMaker, as an available tool for maintaining a replica of an existing Kafka cluster. This integrated tool for replicating all data in a Kafka cluster to another cluster makes actions like changing clusters, upgrade clusters or have a test cluster but with the correct data, easy and efficient.
What is MirrorMaker?
When MirrorMaker is enabled, all messages are consumed from the source cluster and re-published on the target cluster. I.e data is read from topics in the source cluster and written to a topic with the same name in the destination cluster. This means that you have the option to send data to one cluster, which in turn can be read from both clusters. MirrorMaker can run one or multiple nodes. If you as a customer have a five node cluster, you can enable MirrorMaker on one node or all five of them. A higher number of nodes means faster processing and keeping the cluster in-sync at a better rate.
Please note that MirrorMaker might steal some performance from the chosen nodes, which may affect the performance of the Kafka broker on that node.
Go to our control panel to set up your MirrorMaker. From here, you can easily start/stop, and configure MirrorMaker.
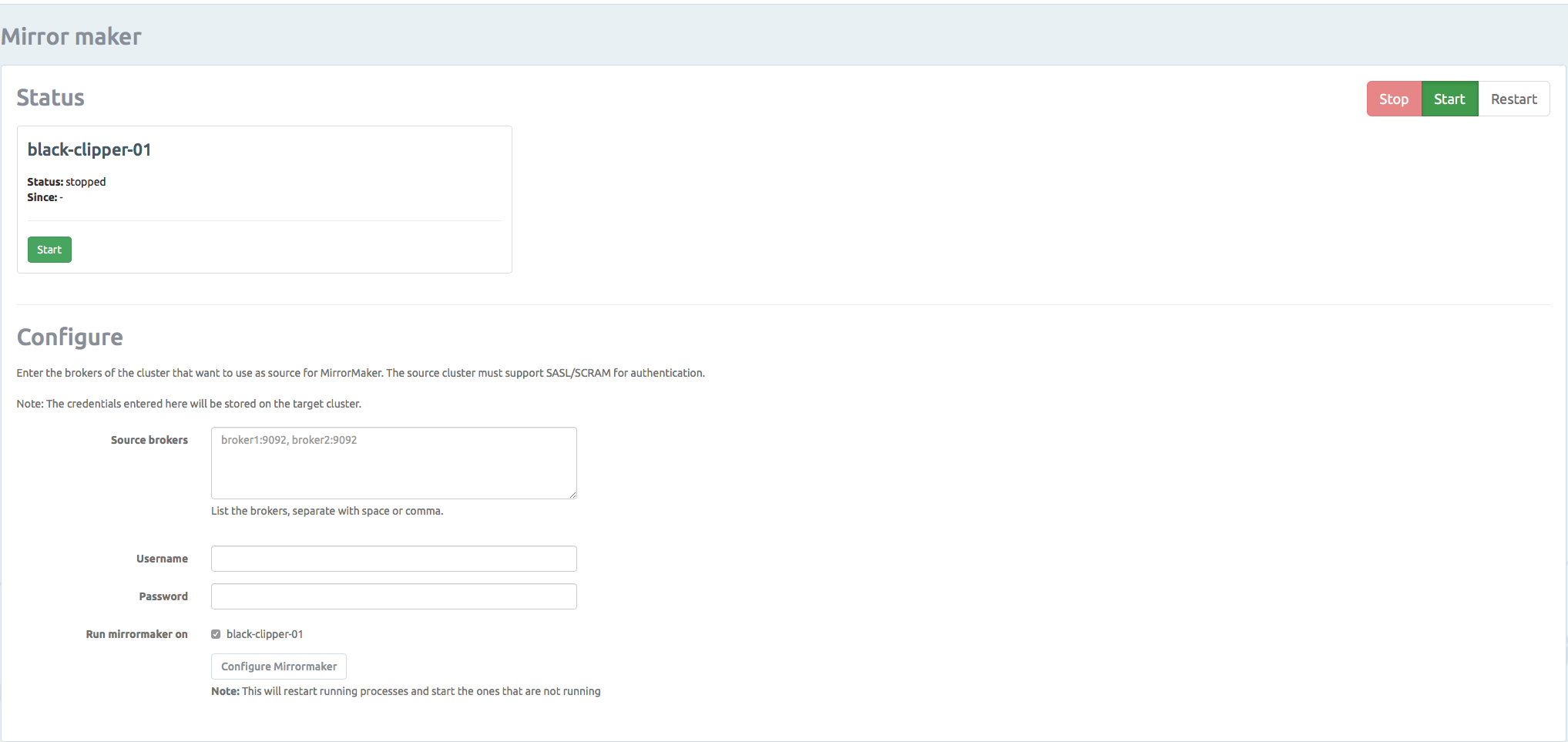
MirrorMaker Best Practices
Here we share some of the MirrorMaker best practices, to enhance the experience of Mirror Maker.
Topics
To make sure that the target cluster has the same setup as the source cluster you are recommended to create topics beforehand and configure them to have the same number of partitions. If you don’t do this MirrorMaker will create the topics for you, but it’s not guaranteed to have the same configuration.
Performance
We want MirrorMaker to run as fast as possible to ensure that the target cluster is always in sync and that MirrorMaker doesn’t have too much data in memory. The default configuration for MirrorMaker will work for all use cases, but based on your setup it can be optimized. The most important setting is num.streams. num.streams tells MirrorMaker how many streams it should start. This is important because MirrorMaker runs one consumer for each stream and you want one consumer for each partition.
Example
You have a Kafka cluster with two topics, and each topic has six partitions. You want to replicate this to a new Kafka cluster which runs on three nodes. The optimal setup would be to have 12 (2*6) consumers. So if we start MirrorMaker on each of the three nodes in the target cluster, each instance should have num.streams=4. MirrorMaker on CloudKarafka is configured as default to run with num.streams=1. If this doesn’t match your needs, please let us know, and we will help you configure this.
Feel free to send us any feedback you might have at support@cloudkarafka.com
